{kind=link}

Most text to video models generate a single clip from a prompt and then stop. They do not keep an internal world state that persists as actions arrive over time. PAN, a new model from MBZUAI’s Institute of Foundation Models, is designed to fill that gap by acting as a general world model that predicts future world states as video, conditioned on history and natural language actions.
From video generator to interactive world simulator
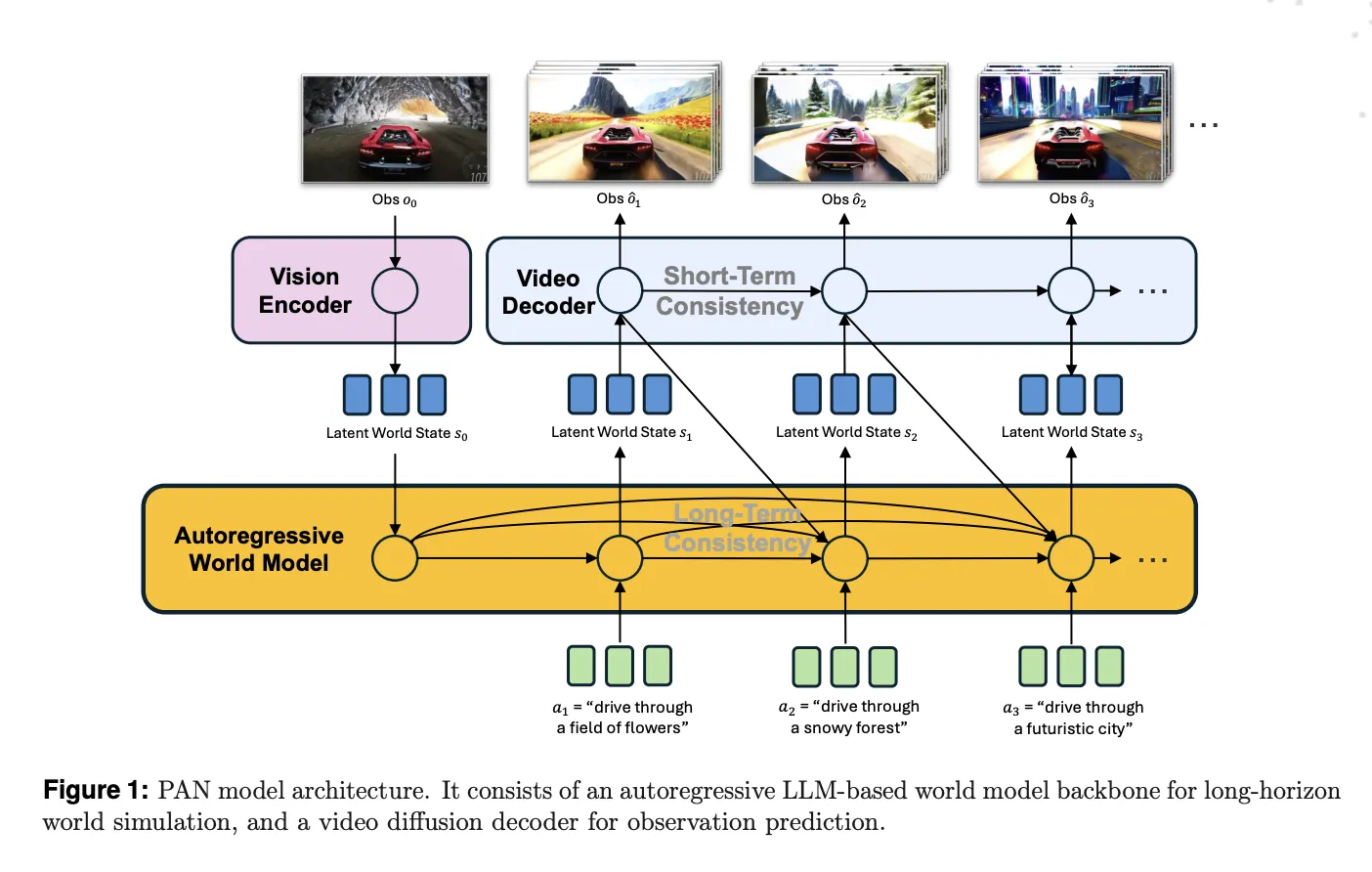
PAN is defined as a general, interactable, long horizon world model. It maintains an internal latent state that represents the current world, then updates that state when it receives a natural language action such as ‘turn left and speed up’ or ‘move the robot arm to the red block.’ The model then decodes the updated state into a short video segment that shows the consequence of that action. This cycle repeats, so the same world state evolves across many steps.
This design allows PAN to support open domain, action conditioned simulation. It can roll out counterfactual futures for different action sequences. An external agent can query PAN as a simulator, compare predicted futures, and choose actions based on those predictions.
GLP architecture, separating what happens from how it looks
The base of PAN is the Generative Latent Prediction, GLP, architecture. GLP separates world dynamics from visual rendering. First, a vision encoder maps images or video frames into a latent world state. Second, an autoregressive latent dynamics backbone based on a large language model predicts the next latent state, conditioned on history and the current action. Third, a video diffusion decoder reconstructs the corresponding video segment from that latent state.

In PAN, the vision encoder and backbone are built on Qwen2.5-VL-7B-Instruct. The vision tower tokenizes frames into patches and produces structured embeddings. The language backbone runs over a history of world states and actions, plus learned query tokens, and outputs the latent representation of the next world state. These latents live in the shared multimodal space of the VLM, which helps ground the dynamics in both text and vision.
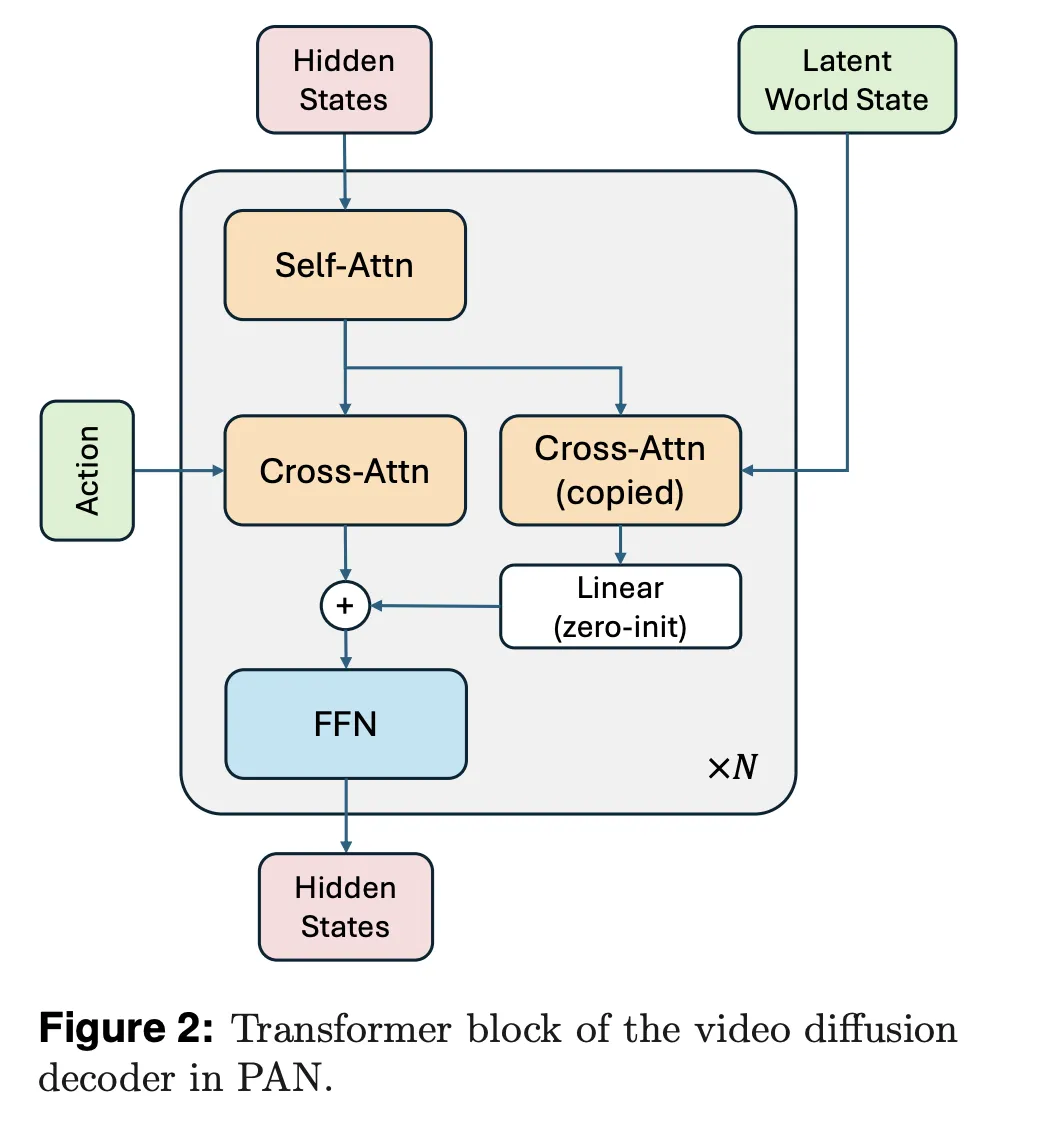
The video diffusion decoder is adapted from Wan2.1-T2V-14B, a diffusion transformer for high fidelity video generation. The research team trains this decoder with a flow matching objective, using one thousand denoising steps and a Rectified Flow formulation. The decoder conditions on both the predicted latent world state and the current natural language action, with a dedicated cross attention stream for the world state and another for the action text.
Causal Swin DPM and sliding window diffusion
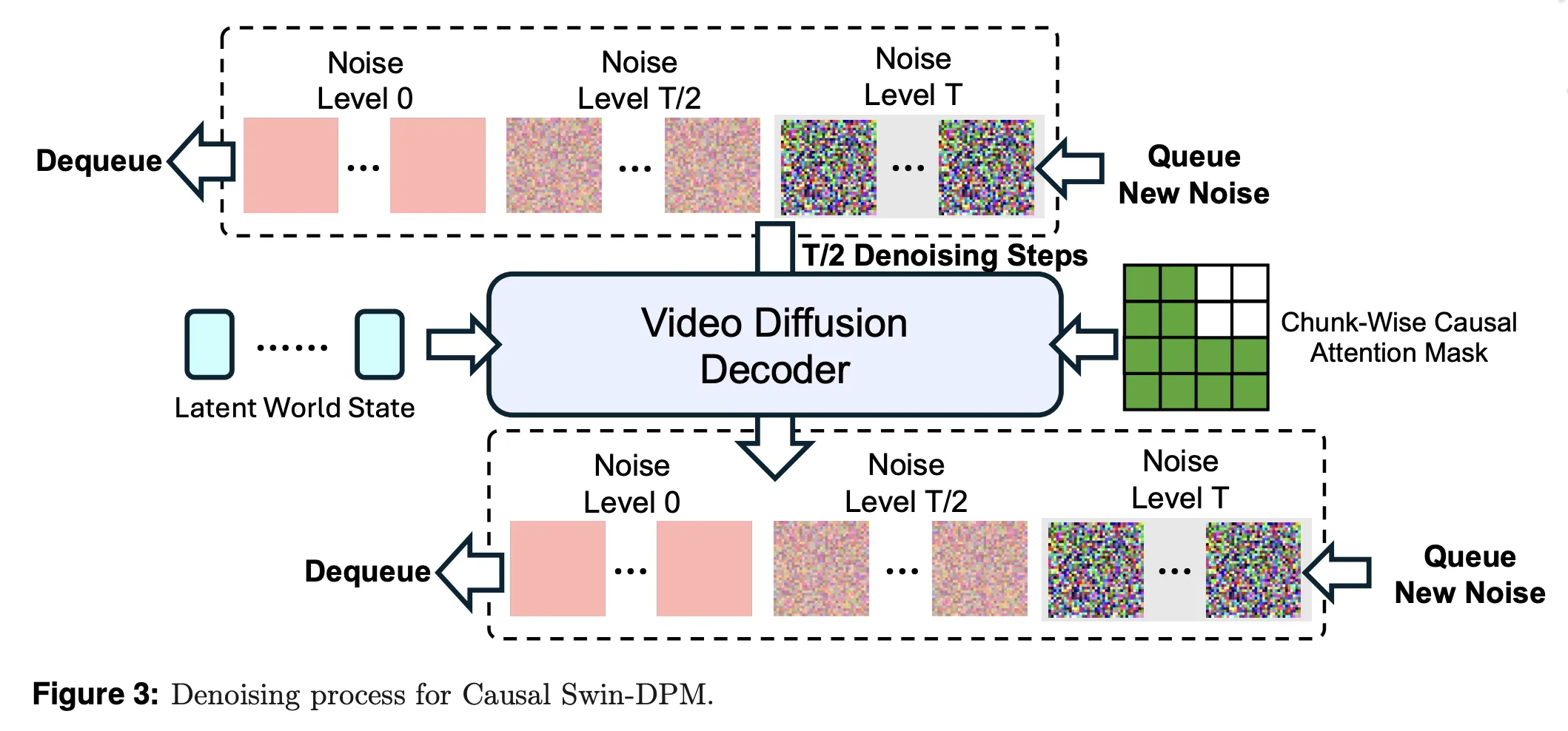
Naively chaining single shot video models by conditioning only on the last frame leads to local discontinuities and rapid quality degradation over long rollouts. PAN addresses this with Causal Swin DPM, which augments the Shift Window Denoising Process Model with chunk wise causal attention.
The decoder operates on a sliding temporal window that holds two chunks of video frames at different noise levels. During denoising, one chunk moves from high noise to clean frames and then leaves the window. A new noisy chunk enters at the other end. Chunk wise causal attention ensures that the later chunk can only attend to the earlier one, not to unseen future actions. This keeps transitions between chunks smooth and reduces error accumulation over long horizons.
PAN also adds controlled noise to the conditioning frame, rather than using a perfectly sharp frame. This suppresses incidental pixel details that do not matter for dynamics and encourages the model to focus on stable structure such as objects and layout.
Training stack and data construction
PAN is trained in two stages. In the first stage, the research team adapts Wan2.1 T2V 14B into the Causal Swin DPM architecture. They train the decoder in BFloat16 with AdamW, a cosine schedule, gradient clipping, FlashAttention3 and FlexAttention kernels, and a hybrid sharded data parallel scheme across 960 NVIDIA H200 GPUs.
In the second stage, they integrate the frozen Qwen2.5 VL 7B Instruct backbone with the video diffusion decoder under the GLP objective. The vision language model remains frozen. The model learns query embeddings and the decoder so that predicted latents and reconstructed videos stay consistent. This joint training also uses sequence parallelism and Ulysses style attention sharding to handle long context sequences. Early stopping ends training after 1 epoch once validation converges, even though the schedule allows 5 epochs.
Training data comes from widely used publicly accessible video sources that cover everyday activities, human object interactions, natural environments, and multi agent scenarios. Long form videos are segmented into coherent clips using shot boundary detection. A filtering pipeline removes static or overly dynamic clips, low aesthetic quality, heavy text overlays, and screen recordings using rule based metrics, pretrained detectors, and a custom VLM filter. The research team then re-captions clips with dense, temporally grounded descriptions that emphasize motion and causal events.
Benchmarks, action fidelity, long horizon stability, planning
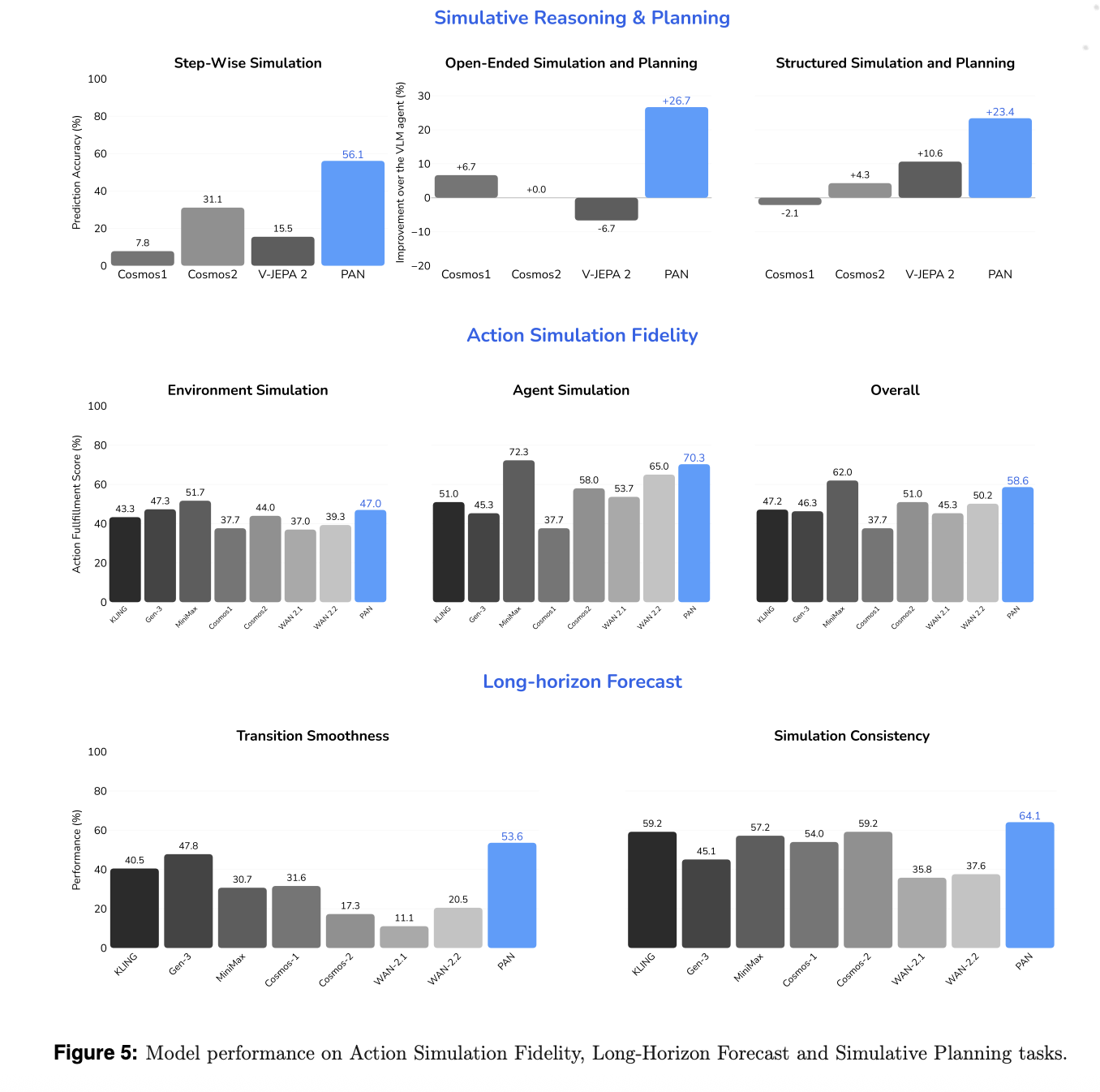
The research team evaluates the model along three axes, action simulation fidelity, long horizon forecast, and simulative reasoning and planning, against both open source and commercial video generators and world models. Baselines include WAN 2.1 and 2.2, Cosmos 1 and 2, V JEPA 2, and commercial systems such as KLING, MiniMax Hailuo, and Gen 3.
For action simulation fidelity, a VLM based judge scores how well the model executes language specified actions while maintaining a stable background. PAN reaches 70.3% accuracy on agent simulation and 47% on environment simulation, for an overall score of 58.6%. It achieves the highest fidelity among open source models and surpasses most commercial baselines.
For long horizon forecast, the research team measures Transition Smoothness and Simulation Consistency. Transition Smoothness uses optical flow acceleration to quantify how smooth motion is across action boundaries. Simulation Consistency uses metrics inspired by WorldScore to monitor degradation over extended sequences. PAN scores 53.6% on Transition Smoothness and 64.1% on Simulation Consistency and exceeds all baselines, including KLING and MiniMax, on these metrics.
For simulative reasoning and planning, PAN is used as an internal simulator inside an OpenAI-o3 based agent loop. In step wise simulation, PAN achieves 56.1% accuracy, the best among open source world models.
Key Takwaways
Comparison Table
PAN is an important step because it operationalizes Generative Latent Prediction with production scale components such as Qwen2.5-VL-7B and Wan2.1-T2V-14B, then validates this stack on well defined benchmarks for action simulation, long horizon forecasting, and simulative planning. The training and evaluation pipeline is clearly documented by the research team, the metrics are reproducible, and the model is released within a transparent world modeling framework rather than as an opaque video demo. Overall, PAN shows how a vision language backbone plus diffusion video decoder can function as a practical world model instead of a pure generative toy.
Check out the Paper, Technical details and Project. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Max is an AI analyst at MarkTechPost, based in Silicon Valley, who actively shapes the future of technology. He teaches robotics at Brainvyne, combats spam with ComplyEmail, and leverages AI daily to translate complex tech advancements into clear, understandable insights